Seq2SeqSharp 2.8.13
See the version list below for details.
dotnet add package Seq2SeqSharp --version 2.8.13
NuGet\Install-Package Seq2SeqSharp -Version 2.8.13
<PackageReference Include="Seq2SeqSharp" Version="2.8.13" />
paket add Seq2SeqSharp --version 2.8.13
#r "nuget: Seq2SeqSharp, 2.8.13"
// Install Seq2SeqSharp as a Cake Addin #addin nuget:?package=Seq2SeqSharp&version=2.8.13 // Install Seq2SeqSharp as a Cake Tool #tool nuget:?package=Seq2SeqSharp&version=2.8.13
Donate a beverage to help me to keep Seq2SeqSharp up to date 😃
![]()
Seq2SeqSharp
Seq2SeqSharp is a high-performance, tensor-based deep neural network framework built in .NET (C#). Designed for sequence-to-sequence, sequence-labeling, sequence-classification tasks, and more, it supports both text and image processing. Seq2SeqSharp is compatible with CPUs and GPUs, running cross-platform on Windows and Linux (x86, x64, and ARM) without modification or recompilation.
Features
Pure C# framework
Transformer encoder and decoder with pointer generator
ision Transformer encoder for image processing
GPTDecoder
Multi-Head Attention and Group Query Attention
Different Activation Functions: ReLU, SiLU, SwiGLU and others
Attention-based LSTM decoder with coverage model
Bi-directional LSTM encoder
Cross-platform support: Windows, Linux, MacOS, and others
Cross-architecture compatibility: X86, X64, and ARM
Pre-built networks for sequence-to-sequence, classification, labeling, and similarity tasks
Mixture of Experts: Easily train large models with reduced computational cost
Automatic Mixed Precision (FP16) support
SentencePiece integration for tokenization
Rotary Positional Embeddings
Layer Normalization and RMS Norm
Python package supported
Tags embeddings mechanism
Prompted Decoders
Includes console tools and web application and api services
Graph-based neural network
Automatic differentiation
Tensor-based operations
Supports both CPUs (via Intel MKL) and multi-GPUs (CUDA)
Optimized CUDA memory management for enhanced performance
Multiple text generation strategies: ArgMax, Beam Search, Top-P Sampling
RMSProp and Adam optimizers
Support for embedding & pre-trained models
Built-in and extendable metrics, including BLEU, Length Ratio, F1 Score, etc.
Generates attention alignment between source and target
ProtoBuf model serialization
Neural network visualization tools
Architecture
Here is the architecture of Seq2SeqSharp
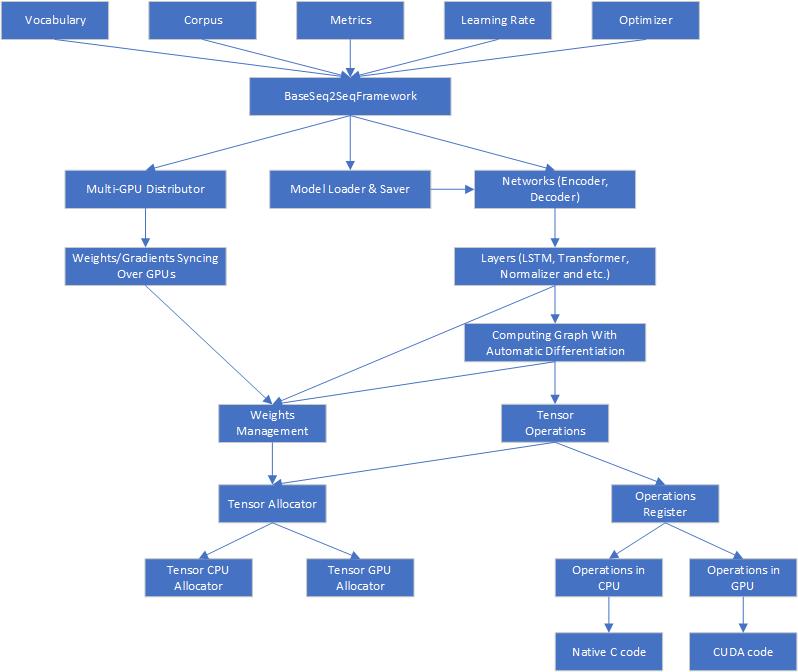
Seq2SeqSharp offers unified tensor operations, ensuring that all tensor computations run identically on both CPUs and GPUs. This allows seamless switching between device types without requiring any code modifications. Additionally, Seq2SeqSharp supports parallel execution of neural networks across multiple GPUs. It automatically handles the distribution and synchronization of weights and gradients across devices, manages resources and models, and more—enabling developers to focus entirely on designing and implementing networks for their specific tasks. Built on .NET Core, Seq2SeqSharp is cross-platform, running on both Windows and Linux without the need for modification or recompilation.
Usage
Seq2SeqSharp offers several command-line tools designed for different types of tasks:
| Name | Comments |
| ------------------------------ | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Seq2SeqConsole | For sequence-to-sequence tasks such as machine translation, automatic summarization, and similar tasks. |
| SeqClassificationConsole | For sequence classification tasks like intent detection. It supports multi-tasking, allowing a single model to be trained or tested for multiple classification tasks. |
| SeqLabelConsole | For sequence labeling tasks such as named entity recognition, part-of-speech tagging, and other similar tasks. |
| GPTConsole | For training and testing GPT-type models, applicable to any text generation tasks. |
It also provides web service APIs for above tasks.
| Name | Comments |
| ---------- | -------------------------------------------------------------------------------------------------------------------- |
| SeqWebAPIs | RESTful web service APIs for various sequence tasks, hosting models trained with Seq2SeqSharp for online inference. |
| SeqWebApps | Web applications designed for sequence-to-sequence and GPT models. |
Seq2SeqConsole for sequence-to-sequence task
Here is the graph that what the model looks like:
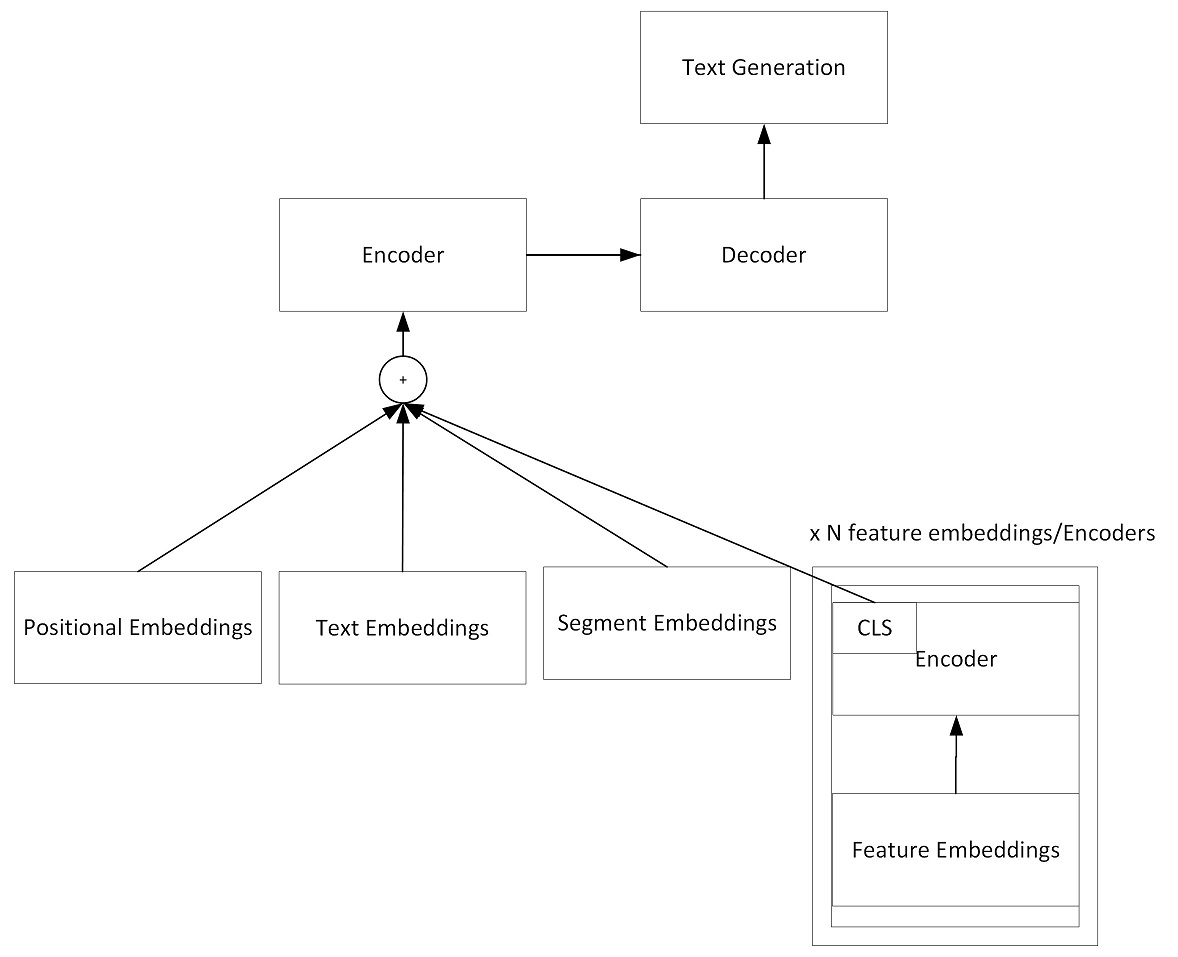
You can use Seq2SeqConsole tool to train, test and visualize models.
Here is the command line to train a model:
Seq2SeqConsole.exe -Task Train [parameters...]
Parameters:
-SrcEmbeddingDim: The embedding dim of source side. Default is 128
-TgtEmbeddingDim: The embedding dim of target side. Default is 128
-HiddenSize: The hidden layer dim of encoder and decoder. Default is 128
-LearningRate: Learning rate. Default is 0.001
-EncoderLayerDepth: The network depth in encoder. The default depth is 1.
-DecoderLayerDepth: The network depth in decoder. The default depth is 1.
-EncoderType: The type of encoder. It supports BiLSTM and Transformer.
-DecoderType: The type of decoder. It supports AttentionLSTM and Transformer.
-MultiHeadNum: The number of multi-heads in Transformer encoder and decoder.
-ModelFilePath: The model file path for training and testing.
-SrcVocab: The vocabulary file path for source side.
-TgtVocab: The vocabulary file path for target side.
-SrcLang: Source language name.
-TgtLang: Target language name.
-TrainCorpusPath: training corpus folder path
-ValidCorpusPath: valid corpus folder path
-GradClip: The clip gradients.
-BatchSize: Batch size for training. Default is 1.
-ValBatchSize: Batch size for testing. Default is 1.
-ExpertNum: The number of experts in MoE (Mixture of Expert) model. Default is 1.
-Dropout: Dropout ratio. Defaul is 0.1
-ProcessorType: Processor type: CPU or GPU(Cuda)
-DeviceIds: Device ids for training in GPU mode. Default is 0. For multi devices, ids are split by comma, for example: 0,1,2
-TaskParallelism: The max degress of parallelism in task. Default is 1
-MaxEpochNum: Maxmium epoch number during training. Default is 100
-MaxSrcSentLength: Maxmium source sentence length on training and test set. Default is 110 tokens
-MaxTgtSentLength: Maxmium target sentence length on training and test set. Default is 110 tokens
-MaxValidSrcSentLength: Maxmium source sentence length on valid set. Default is 110 tokens
-MaxValidTgtSentLength: Maxmium target sentence length on valid set. Default is 110 tokens
-WarmUpSteps: The number of steps for warming up. Default is 8,000
-EnableTagEmbeddings: Enable tag embeddings in encoder. The tag embeddings will be added to token embeddings. Default is false
-CompilerOptions: The options for CUDA NVRTC compiler. Options are split by space. For example: "--use_fast_math --gpu-architecture=compute_60" means to use fast math libs and run on Pascal and above GPUs
-Optimizer: The weights optimizer during training. It supports Adam and RMSProp. Adam is default
-CompilerOptions: The NVRTC compiler options for GPUs. --include-path is required to point to CUDA SDK include path.
Note that if "-SrcVocab" and "-TgtVocab" are empty, vocabulary will be built from training corpus.
Example: Seq2SeqConsole.exe -Task Train -SrcEmbeddingDim 512 -TgtEmbeddingDim 512 -HiddenSize 512 -LearningRate 0.002 -ModelFilePath seq2seq.model -TrainCorpusPath .\corpus -ValidCorpusPath .\corpus_valid -SrcLang ENU -TgtLang CHS -BatchSize 256 -ProcessorType GPU -EncoderType Transformer -EncoderLayerDepth 6 -DecoderLayerDepth 2 -MultiHeadNum 8 -DeviceIds 0,1,2,3,4,5,6,7
During training, the iteration information will be printed out and logged as follows:
info,9/26/2019 3:38:24 PM Update = '15600' Epoch = '0' LR = '0.002000', Current Cost = '2.817434', Avg Cost = '3.551963', SentInTotal = '31948800', SentPerMin = '52153.52', WordPerSec = '39515.27'
info,9/26/2019 3:42:28 PM Update = '15700' Epoch = '0' LR = '0.002000', Current Cost = '2.800056', Avg Cost = '3.546863', SentInTotal = '32153600', SentPerMin = '52141.86', WordPerSec = '39523.83'
Here is the command line to valid models
Seq2SeqConsole.exe -Task Valid [parameters...]
Parameters:
-ModelFilePath: The trained model file path.
-SrcLang: Source language name.
-TgtLang: Target language name.
-ValidCorpusPath: valid corpus folder path
Example: Seq2SeqConsole.exe -Task Valid -ModelFilePath seq2seq.model -SrcLang ENU -TgtLang CHS -ValidCorpusPath .\corpus_valid
Here is the command line to test models
Seq2SeqConsole.exe -Task Test [parameters...]
Parameters:
-InputTestFile: The input file for test.
-OutputFile: The test result file.
-OutputPromptFile: The prompt file for output. It is a input file along with input test file.
-OutputAlignmentsFile: The output file that contains alignments between target sequence and source sequence. It only works for pointer-generator enabled model.
-ModelFilePath: The trained model file path.
-ProcessorType: Architecture type: CPU or GPU
-DeviceIds: Device ids for training in GPU mode. Default is 0. For multi devices, ids are split by comma, for example: 0,1,2
-BeamSearchSize: Beam search size. Default is 1
-MaxSrcSentLength: Maxmium source sentence length on valid/test set. Default is 110 tokens
-MaxTgtSentLength: Maxmium target sentence length on valid/test set. Default is 110 tokens
Example: Seq2SeqConsole.exe -Task Test -ModelFilePath seq2seq.model -InputTestFile test.txt -OutputFile result.txt -ProcessorType CPU -BeamSearchSize 5 -MaxSrcSentLength 100 -MaxTgtSentLength 100
You can also keep all parameters into a json file and run Seq2SeqConsole.exe -ConfigFilePath <config_file_path> Here is an example for training.
{
"DecoderLayerDepth": 6,
"DecoderStartLearningRateFactor": 1.0,
"DecoderType": "Transformer",
"EnableCoverageModel": false,
"IsDecoderTrainable": true,
"IsSrcEmbeddingTrainable": true,
"IsTgtEmbeddingTrainable": true,
"MaxValidSrcSentLength": 110,
"MaxValidTgtSentLength": 110,
"MaxSrcSentLength": 110,
"MaxTgtSentLength": 110,
"SeqGenerationMetric": "BLEU",
"SharedEmbeddings": true,
"TgtEmbeddingDim": 512,
"PointerGenerator": true,
"BatchSize": 64,
"MaxTokenSizePerBatch": 5120,
"BeamSearchSize": 1,
"Beta1": 0.9,
"Beta2": 0.98,
"CompilerOptions": "--use_fast_math --gpu-architecture=compute_70 --include-path=<CUDA SDK Include Path>",
"ConfigFilePath": "",
"DecodingStrategy": "GreedySearch",
"DecodingRepeatPenalty": 2.0,
"DeviceIds": "0",
"DropoutRatio": 0.0,
"EnableSegmentEmbeddings": false,
"ExpertNum": 1,
"ExpertsPerTokenFactor": 1,
"MaxSegmentNum": 16,
"EncoderLayerDepth": 6,
"SrcEmbeddingDim": 512,
"EncoderStartLearningRateFactor": 1.0,
"EncoderType": "Transformer",
"FocalLossGamma": 0.0,
"GradClip": 5.0,
"HiddenSize": 512,
"IntermediateSize": 2048,
"IsEncoderTrainable": true,
"LossType": "CrossEntropy",
"MaxEpochNum": 100,
"MemoryUsageRatio": 0.99,
"ModelFilePath": "mt_enu_chs.model",
"MultiHeadNum": 8,
"NotifyEmail": "",
"Optimizer": "Adam",
"ProcessorType": "GPU",
"MKLInstructions": "AVX2",
"SrcLang": "SRC",
"StartLearningRate": 0.0006,
"PaddingType": "NoPadding",
"Task": "Train",
"TooLongSequence": "Ignore",
"ActivateFunc": "SiLU",
"LearningRateType": "CosineDecay",
"PEType": "RoPE",
"NormType": "LayerNorm",
"LogVerbose": "Normal",
"TgtLang": "TGT",
"TrainCorpusPath": ".\\data\\train",
"ValidCorpusPaths": ".\\data\\valid",
"SrcVocab": null,
"TgtVocab": null,
"TaskParallelism": 1,
"UpdateFreq": 2,
"ValMaxTokenSizePerBatch": 500,
"StartValidAfterUpdates": 10000,
"RunValidEveryUpdates": 10000,
"WarmUpSteps": 8000,
"WeightsUpdateCount": 0,
"SrcVocabSize": 45000,
"TgtVocabSize": 45000,
"EnableTagEmbeddings": false
}
Data Format for Seq2SeqConsole tool
The training/valid corpus contain each sentence per line. The file name pattern is "mainfilename.{source language name}.snt" and "mainfilename.{target language name}.snt".
For example: Let's use three letters name CHS for Chinese and ENU for English in Chinese-English parallel corpus, so we could have these corpus files: train01.enu.snt, train01.chs.snt, train02.enu.snt and train02.chs.snt.
In train01.enu.snt, assume we have below two sentences:
the children huddled together for warmth .
the car business is constantly changing .
So, train01.chs.snt has the corresponding translated sentences:
孩子 们 挤 成 一 团 以 取暖 .
汽车 业 也 在 不断 地 变化 .
To apply contextual features, you can append features to the line of input text and split them by tab character.
Here is an example. Let's assume we have a translation model that can translate English to Chinese, Japanese and Korean, so given a English sentence, we need to apply a contextual feature to let the model know which language it should translate to.
In train01.enu.snt, the input will be changed to:
the children huddled together for warmth . \t CHS
the car business is constantly changing . \t CHS
But train01.cjk.snt is the same as train01.chs.snt in above.
孩子 们 挤 成 一 团 以 取暖 .
汽车 业 也 在 不断 地 变化 .
Prompt decoding
Beside decoding entire sequence from the scratch, Seq2SeqConsole also supports to decode sequence by given prompts.
Here is an example of machine translation model from English to CJK (Chinese, Japanese and Korean). This single model is able to translate sentence from English to any CJK language. The input sentence is normal English, and then you give the decoder a prompt for translation.
For example: given the input sentence "▁i ▁would ▁like ▁to ▁drink ▁with ▁you ." (Note that it has been tokenized by sentence piece model) and different prompt for decoder, the model will translate it to different languages.
| Prompt | Translated Sentence |
|---|---|
| <CHS> | <CHS> ▁我想 和你一起 喝酒 。 |
| <JPN> | <JPN> ▁ あなたと 飲み たい |
| <KOR> | <KOR> ▁나는 ▁당신과 ▁함께 ▁마시 길 ▁바랍니다 . |
GPTConsole for GPT decoder only model training and testing
GPTConsole is a command line tool for GPT style model training and testing. Given text in input file per line, the model will continue generating the rest of text.
This tool is pretty similiar to Seq2SeqConsole and most of parameters are reusable. The main difference is that GPTConsole does not have settings for source side and encoders. Its all settings are for target side and decoder only.
ImgSeqConsole is for image caption task
ImgSeqConsole is a command line tool for image caption task. Given a list of image file path, the model will generate descriptions of these images.
SeqClassification for sequence-classification task
SeqClassification is used to classify input sequence to a certain category. Given an input sequence, the tool will add a [CLS] tag at the beginning of sequence, and then send it to the encoder. At top layer of the encoder, it will run softmax against [CLS] and decide which category the sequence belongs to.
This tool can be used to train a model for sequence-classification task, and test the model.
Here is the graph that what the model looks like:
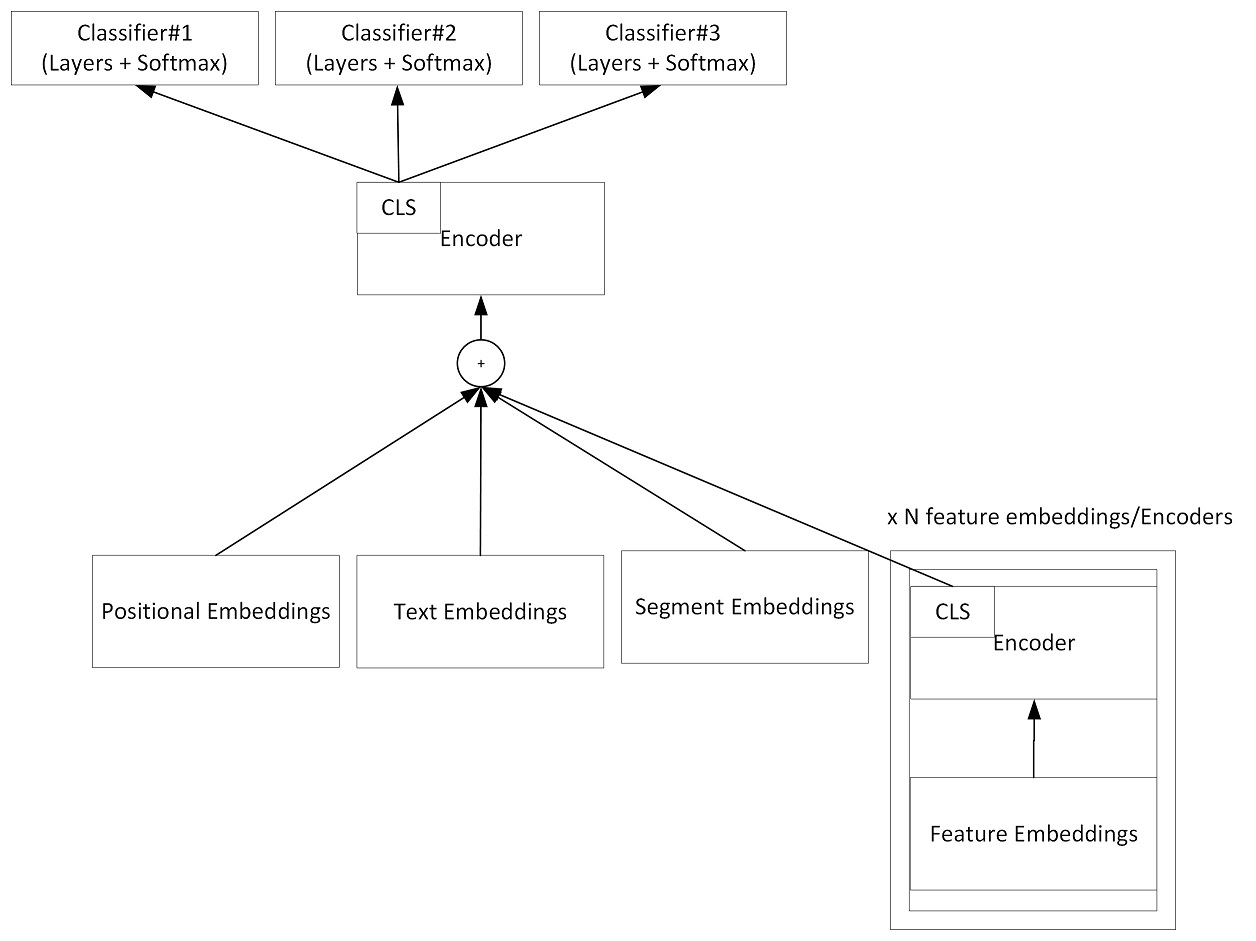
Here is the configuration file for model training.
{
"Task":"Train",
"EmbeddingDim":512,
"HiddenSize":512,
"IntermediateSize": 2048,
"StartLearningRate":0.0006,
"WeightsUpdateCount":0,
"EnableSegmentEmbeddings":true,
"EncoderLayerDepth":6,
"ModelFilePath":"seq2seq_turn_cls.model",
"TrainCorpusPath":"./data/train",
"ValidCorpusPaths":"./data/test",
"SrcLang":"SRC",
"TgtLang":"CLS",
"InputTestFile":null,
"OutputFile":null,
"GradClip":5.0,
"BatchSize": 1,
"MaxTokenSizePerBatch": 5120,
"ValBatchSize":1,
"DropoutRatio":0.0,
"ProcessorType":"GPU",
"EncoderType":"Transformer",
"MultiHeadNum":8,
"DeviceIds":"0,1",
"TaskParallelism": 2,
"MaxEpochNum":100,
"MaxSentLength":5120,
"WarmUpSteps":8000,
"VisualizeNNFilePath":null,
"Beta1":0.9,
"Beta2":0.98,
"EnableCoverageModel":false,
"StartValidAfterUpdates": 20000,
"RunValidEveryUpdates": 10000,
"VocabSize":45000,
"PaddingType": "NoPadding",
"CompilerOptions":"--use_fast_math --gpu-architecture=compute_70"
}
Data format for SeqCliassificationConsole tool
It also uses two files for each pair of data and follows the same naming convention as Seq2SeqConsole tool in above. The source file includes tokens as input to the model, and the target file includes the corresponding tags that model will predict. Each line contains one record.
Here is an example:
| Tag | Tokens in Sequence |
| -------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Otorhinolaryngology | What should I do if I have a sore throat and a runny nose? [SEP] I feel sore in my throat after getting up in the morning, and I still have clear water in my nose. I measure my body temperature and I don’t have a fever. Have you caught a cold? What medicine should be taken. |
| Orthopedics | How can I recuperate if my ankle is twisted? [SEP] I twisted my ankle when I went down the stairs, and now it is red and swollen. X-rays were taken and there were no fractures. May I ask how to recuperate to get better as soon as possible. |
"Otorhinolaryngology" and "Orthopedics" are tags for classification and the rest of the tokens in each line are tokens for input sequence. This is an example that given title and description in medical domain, asking model to predict which specialty it should be classified. [SEP] is used to split title and description in the sequence, but it's not required in other tasks.
SeqLabelConsole for sequence-labeling task
The usage of SeqLabelConsole.exe is similar as Seq2SeqConsole.exe in above, you can just type it in the console and it will show you usage.
Data format for SeqLabelConsole tool
The data format is one token along with the corresponding tag per line. Tokens are inputs for model training, and tags are what the model trys to predict during the training.
Token and tags are split by tab character. It looks like [Token] \t [Tag] And each sentence is split by a blank line. This format is compatible with the data for CRFSharp and CRF++.
Here is an example:
In train_001.txt, assume we have two sentences. For sentence "Microsoft is located in Redmond .", "Microsoft" is organization name, "Redmond" is location name. For sentence "Zhongkai Fu is the author of Seq2SeqSharp .", "Zhongkai Fu" is person name and "Seq2SeqSharp" is software name. So, the training corpus should look likes:
| Token | Tag |
| ------------ | ------- |
| Microsoft | S_ORG |
| is | S_NOR |
| located | S_NOR |
| in | S_NOR |
| Redmond | S_LOC |
| . | S_NOR |
| [BLANK] | [BLANK] |
| Zhongkai | B_PER |
| Fu | E_PER |
| is | S_NOR |
| the | S_NOR |
| author | S_NOR |
| of | S_NOR |
| Seq2SeqSharp | S_SFT |
| . | S_NOR |
Here is the configuration file for model training.
{
"Task":"Train",
"SrcEmbeddingDim":512,
"HiddenSize":512,
"IntermediateSize": 2048,
"StartLearningRate":0.0006,
"WeightsUpdateCount":0,
"EncoderLayerDepth":6,
"ModelFilePath":"medNer.model",
"SrcVocab":null,
"TgtVocab":null,
"SrcVocabSize":300000,
"TgtVocabSize":300000,
"SharedEmbeddings":false,
"SrcEmbeddingModelFilePath":null,
"TgtEmbeddingModelFilePath":null,
"TrainCorpusPath":".\\train.snt",
"ValidCorpusPaths":null,
"InputTestFile":null,
"OutputTestFile":null,
"PaddingType":"NoPadding",
"LearningRateType": "CosineDecay",
"GradClip":5.0,
"BatchSize": 1,
"MaxTokenSizePerBatch": 5120,
"ValBatchSize":128,
"DropoutRatio":0,
"ProcessorType":"GPU",
"EncoderType":"Transformer",
"MultiHeadNum":8,
"DeviceIds":"0",
"TaskParallelism": 1,
"BeamSearchSize":1,
"MaxEpochNum":100,
"MaxSentLength":110,
"WarmUpSteps":8000,
"VisualizeNNFilePath":null,
"Beta1":0.9,
"Beta2":0.98,
"StartValidAfterUpdates": 20000,
"RunValidEveryUpdates": 10000,
"EnableCoverageModel":false,
"CompilerOptions":"--use_fast_math --gpu-architecture=compute_70",
"Optimizer":"Adam"
}
Demos and released models
From 2.7.0 version, Seq2SeqSharp models are deployed on Hugging Face and you can also play demos there.
| Demo | Hugging Face Space Url | Hugging Face Model Url | Model Parameters |
| ------------------------------------------------------ | ------------------------------------------------------- | ----------------------------------------------- | ----------------------- |
| Machine Translation from English to Chinese | https://huggingface.co/spaces/zhongkaifu/mt_enu_chs | https://huggingface.co/zhongkaifu/mt_enu_chs | 117M (Encoder-Decoder) |
| Machine Translation from Chinese to English | https://huggingface.co/spaces/zhongkaifu/mt_chs_enu | https://huggingface.co/zhongkaifu/mt_chs_enu | 117M (Encoder-Decoder) |
| Machine Translation from Japanese or Korean to Chinese | https://huggingface.co/spaces/zhongkaifu/mt_jpnkor_chs | https://huggingface.co/zhongkaifu/mt_jpnkor_chs | 117M (Encoder-Decoder) |
| Chinese Medical Question and Answer Demo | https://huggingface.co/spaces/zhongkaifu/medical_qa_chs | https://huggingface.co/zhongkaifu/qa_med_chs | 117M (Encoder-Decoder) |
| Chinese fiction writer | https://huggingface.co/spaces/zhongkaifu/story_writing | https://huggingface.co/zhongkaifu/story_writing | 2B (Decoder only) |
To deploy binary files and models, you can check Dockerfile in Hugging Face Space urls or "Build & Deployment" section in this document.
Here is an example that asking model to continue writing story after "May the force be with you.".
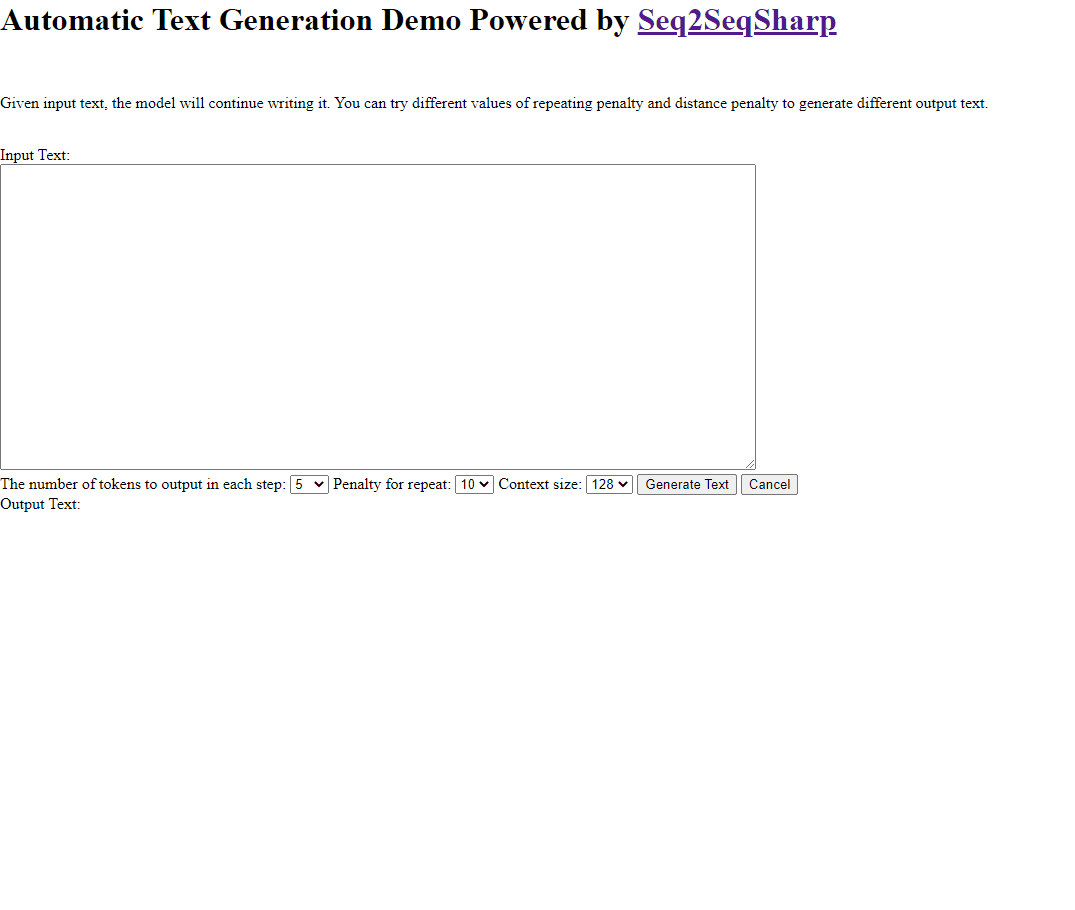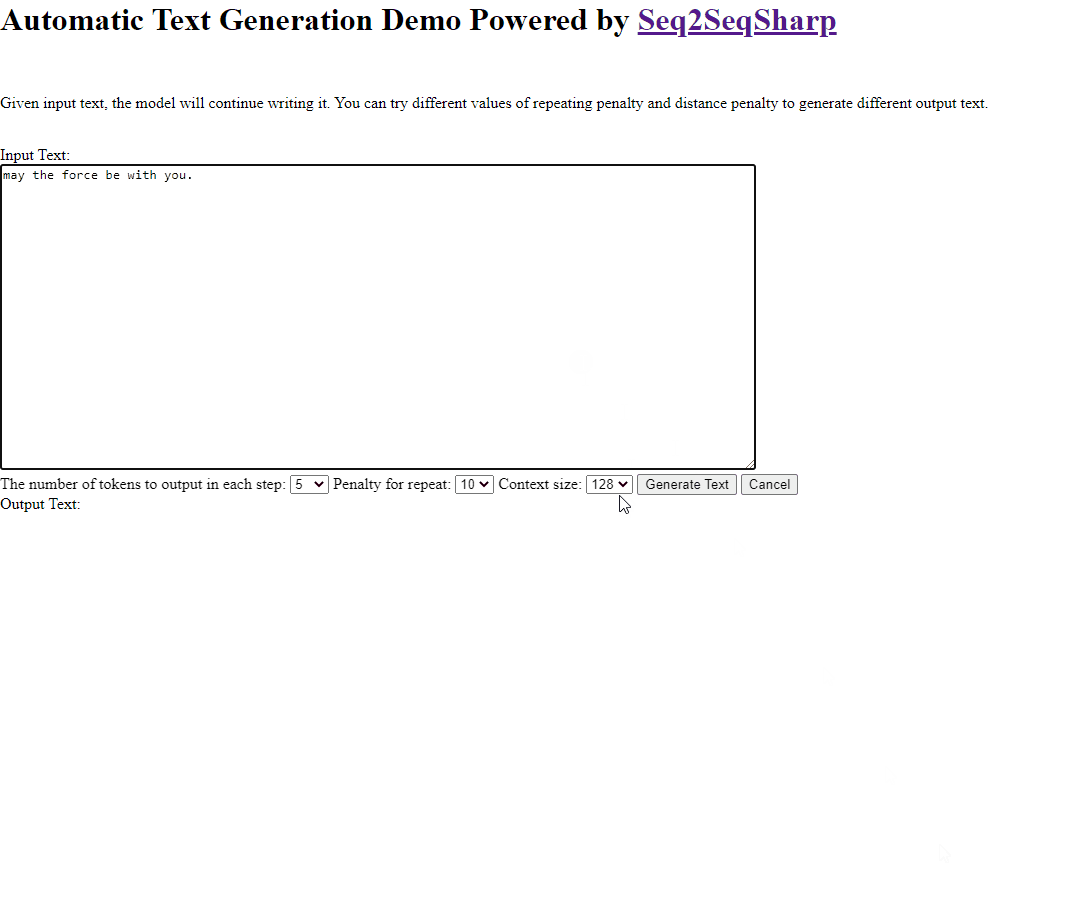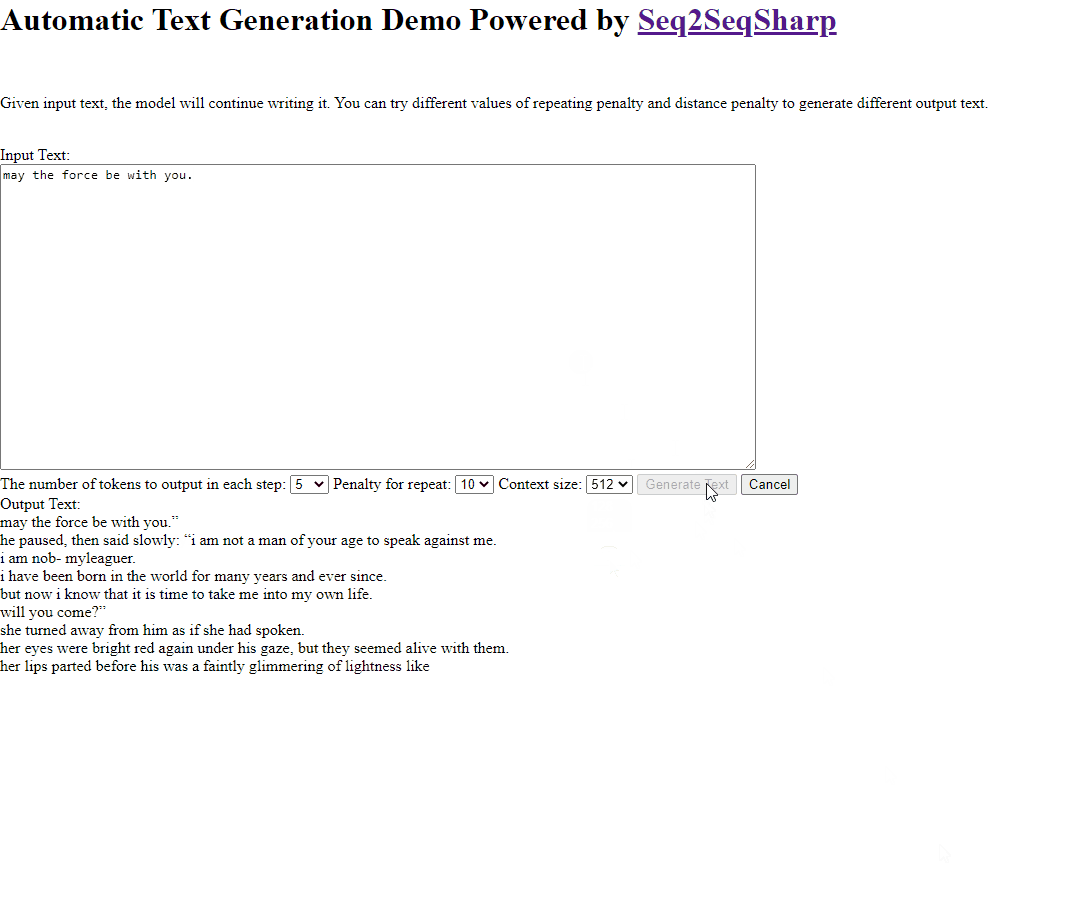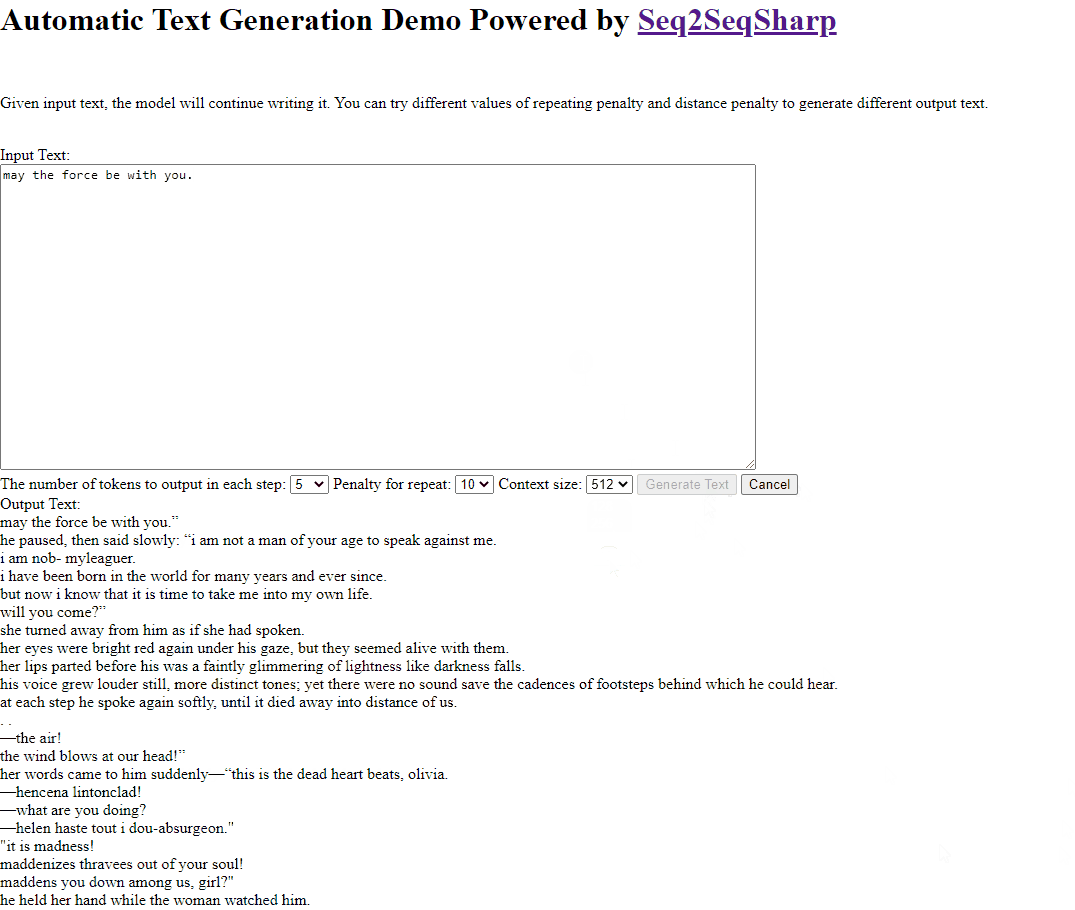
Build & Deployment
You can build and deploy Seq2SeqSharp and its tool by many different ways. Here is an example that creating Docker image for SeqWebApps.
Dockerfile:
FROM python:3.9
WORKDIR /code
COPY ./requirements.txt /code/requirements.txt
RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt
RUN wget https://packages.microsoft.com/config/ubuntu/18.04/packages-microsoft-prod.deb -O packages-microsoft-prod.deb
RUN dpkg -i packages-microsoft-prod.deb
RUN rm packages-microsoft-prod.deb
RUN curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh
# Install .NET SDK
RUN apt-get update
RUN apt-get install -y dotnet-sdk-7.0
RUN apt-get install -y aspnetcore-runtime-7.0
RUN apt-get install -y cmake
RUN apt-get install -y git-lfs
# Install Intel MKL
RUN wget https://apt.repos.intel.com/intel-gpg-keys/GPG-PUB-KEY-INTEL-SW-PRODUCTS-2019.PUB
RUN apt-key add GPG-PUB-KEY-INTEL-SW-PRODUCTS-2019.PUB
RUN sh -c 'echo deb https://apt.repos.intel.com/mkl all main > /etc/apt/sources.list.d/intel-mkl.list'
RUN apt-get update
RUN apt-get install -y intel-mkl-64bit-2020.4.912
RUN echo "/opt/intel/lib/intel64" > /etc/ld.so.conf.d/mkl.conf
RUN echo "/opt/intel/mkl/lib/intel64" >> /etc/ld.so.conf.d/mkl.conf
RUN ldconfig
# Clone Seq2SeqSharp
RUN git clone https://github.com/zhongkaifu/Seq2SeqSharp.git
WORKDIR /code/Seq2SeqSharp
RUN dotnet build Seq2SeqSharp.sln --configuration Release
# Build customized SentencePiece
WORKDIR /code/Seq2SeqSharp/ExternalProjects
RUN unzip SentencePiece.zip
WORKDIR /code/Seq2SeqSharp/ExternalProjects/SentencePiece
RUN mkdir build
WORKDIR /code/Seq2SeqSharp/ExternalProjects/SentencePiece/build
RUN cmake ..
RUN make -j $(nproc)
RUN make install
RUN ldconfig -v
WORKDIR /code
RUN mkdir -p /code/bin
RUN chmod 777 /code/bin
WORKDIR /code/bin
# Deploy models, vocabulary and config files
RUN cp -r /code/Seq2SeqSharp/Tools/SeqWebApps/bin/Release/net7.0/* .
RUN wget https://huggingface.co/zhongkaifu/story_writing/resolve/main/story_base.model
RUN wget https://huggingface.co/zhongkaifu/story_writing/resolve/main/chsYBSpm.model
RUN rm appsettings.json
RUN wget https://huggingface.co/zhongkaifu/story_writing/resolve/main/appsettings.json
ENV MKL_ENABLE_INSTRUCTIONS=AVX2
# Run application
CMD ["dotnet","/code/bin/SeqWebApps.dll"]
Python package
Seq2SeqSharp released Python package and you can get it from https://pypi.org/project/Seq2SeqSharp/ or run command line "pip install Seq2SeqSharp"
The package is built based on PythonNet, and you could call Seq2SeqSharp APIs in your Python code. You can check train and test example codes in PyPackage folder.
Here is an Python example to test English-Chinese machine translation model trained by Seq2SeqSharp.
from Seq2SeqSharp import Seq2SeqOptions, ModeEnums, ProcessorTypeEnums, DecodingStrategyEnums, Seq2Seq
opts = Seq2SeqOptions()
opts.Task = ModeEnums.Test
opts.ModelFilePath = "../Tests/Seq2SeqSharp.Tests/mt_enu_chs.model"
opts.InputTestFile = "test.src"
opts.OutputFile = "a.out"
opts.ProcessorType = ProcessorTypeEnums.CPU
opts.MaxSrcSentLength = 110
opts.MaxTgtSentLength = 110
opts.BatchSize = 1
opts.SrcSentencePieceModelPath = "./enu.model"
opts.TgtSentencePieceModelPath = "./chs.model"
decodingOptions = opts.CreateDecodingOptions()
ss = Seq2Seq(opts)
ss.Test(opts.InputTestFile, opts.OutputFile, opts.BatchSize, decodingOptions, opts.SrcSentencePieceModelPath, opts.TgtSentencePieceModelPath, "")
And here is another Python example to train English-Chinese machine translation model by Seq2SeqSharp.
from Seq2SeqSharp import Seq2SeqOptions, ModeEnums, ProcessorTypeEnums, Seq2Seq, Vocab, Seq2SeqCorpus, DecayLearningRate, BleuMetric, Misc, TooLongSequence, PaddingEnums, AdamOptimizer
import json
def ParseOptions(config_json):
opts = Seq2SeqOptions()
opts.Task = ModeEnums.Train
opts.ProcessorType = ProcessorTypeEnums.CPU
opts.ModelFilePath = config_json['ModelFilePath']
opts.RunValidEveryUpdates = int(config_json['RunValidEveryUpdates'])
opts.UpdateFreq = int(config_json['UpdateFreq'])
opts.StartValidAfterUpdates = int(config_json['StartValidAfterUpdates'])
opts.WeightsUpdateCount = int(config_json['WeightsUpdateCount'])
return opts
with open("train_opts.json", 'r') as file:
opts = json.load(file)
trainCorpus = Seq2SeqCorpus(corpusFilePath = opts['TrainCorpusPath'], srcLangName = opts['SrcLang'], tgtLangName = opts['TgtLang'], maxTokenSizePerBatch = int(opts['MaxTokenSizePerBatch']), maxSrcSentLength = int(opts['MaxSrcSentLength']), maxTgtSentLength = int(opts['MaxTgtSentLength']))
validCorpusList = []
if len(opts['ValidCorpusPaths']) > 0:
validCorpusPaths = opts['ValidCorpusPaths'].split(';')
for validCorpusPath in validCorpusPaths:
validCorpus = Seq2SeqCorpus(validCorpusPath, opts['SrcLang'], opts['TgtLang'], int(opts['ValMaxTokenSizePerBatch']), int(opts['MaxValidSrcSentLength']), int(opts['MaxValidTgtSentLength']))
validCorpusList.append(validCorpus)
learningRate = DecayLearningRate(opts['StartLearningRate'], opts['WarmUpSteps'], opts['WeightsUpdateCount'], opts['LearningRateStepDownFactor'], opts['UpdateNumToStepDownLearningRate'])
optimizer = AdamOptimizer(opts['GradClip'], opts['Beta1'], opts['Beta2'], opts['SaveGPUMemoryMode'])
metrics = []
metrics.append(BleuMetric())
srcVocab = Vocab(opts['SrcVocab'])
tgtVocab = Vocab(opts['TgtVocab'])
opts2 = ParseOptions(opts)
decodingOptions = opts2.CreateDecodingOptions()
ss = Seq2Seq(opts2, srcVocab, tgtVocab)
ss.Train(maxTrainingEpoch = opts['MaxEpochNum'], trainCorpus = trainCorpus, validCorpusList = validCorpusList, learningRate = learningRate, optimizer = optimizer, metrics = metrics, decodingOptions = decodingOptions);
Using different CUDA versions and .NET versions
Seq2SeqSharp uses CUDA 12.x and .NET 7.0 by default, but you can still use different versions of them. It has already been tested on .NET core 3.1, CUDA 10.x and some other versions.
For different .NET versions, you need to modify target framework in *.csproj files. Here is an example to use .net core 3.1 as target framework in Seq2SeqSharp.csproj file.
<PropertyGroup>
<TargetFramework>netcoreapp3.1</TargetFramework>
</PropertyGroup>
Using Intel MKL to speed up training and inference for CPUs
Seq2SeqSharp can use Intel MKL to speed up performance for training and inference. To use Intel MKL, set ProcessorType to CPU_MKL, and copy files in dll folder to your current working directory if you are in Windows. For Linux user, please run apt-get install for intel-mkl-64bit-2020.4-912 or newer version.
Build and run Seq2SeqSharp in Nvidia Jetson
Nvidia Jetson is an advanced platform for edge AI computing. Here is an example that running Seq2SeqSharp on Jetson Nano for Chinese medical QA task.
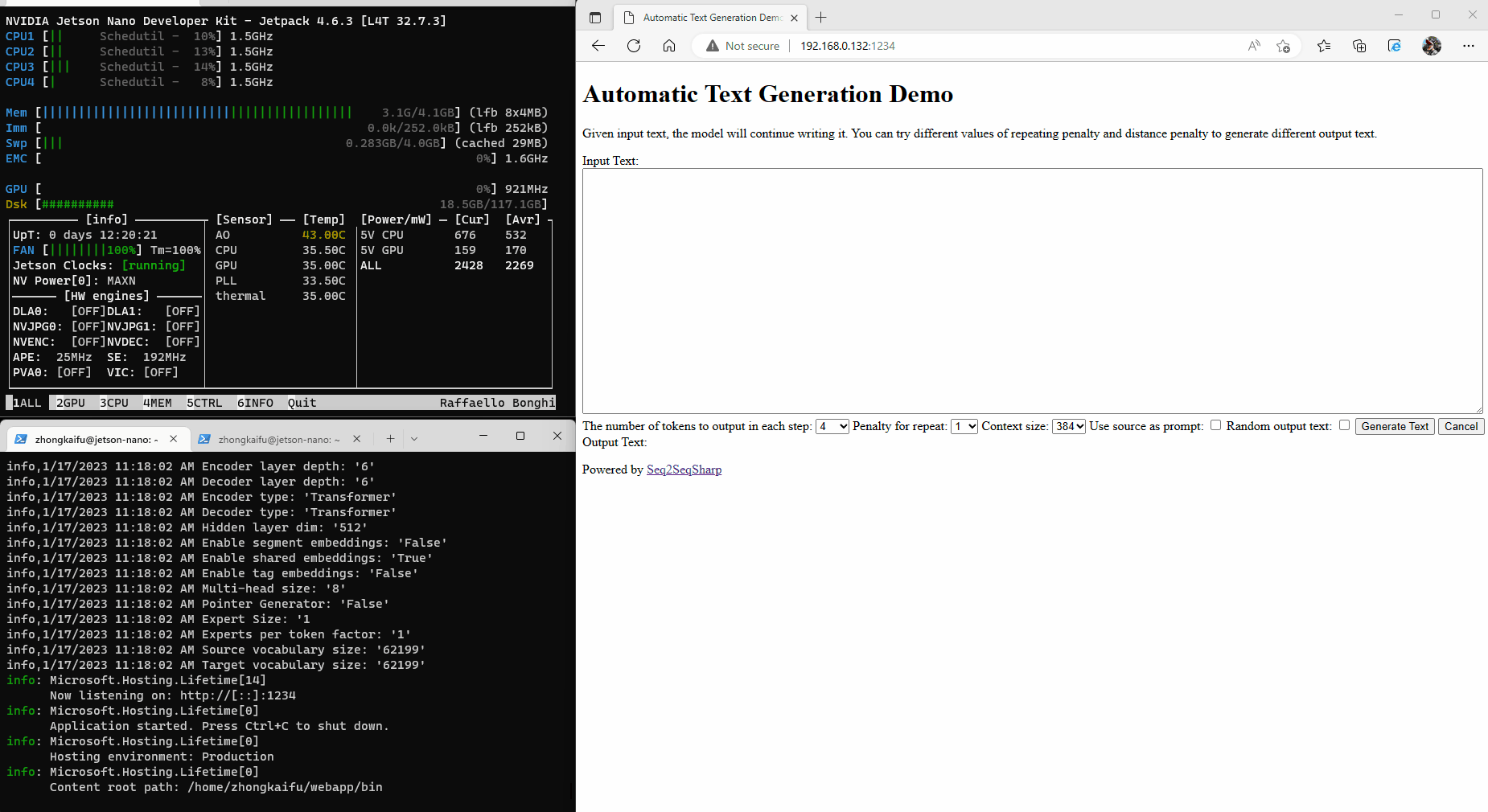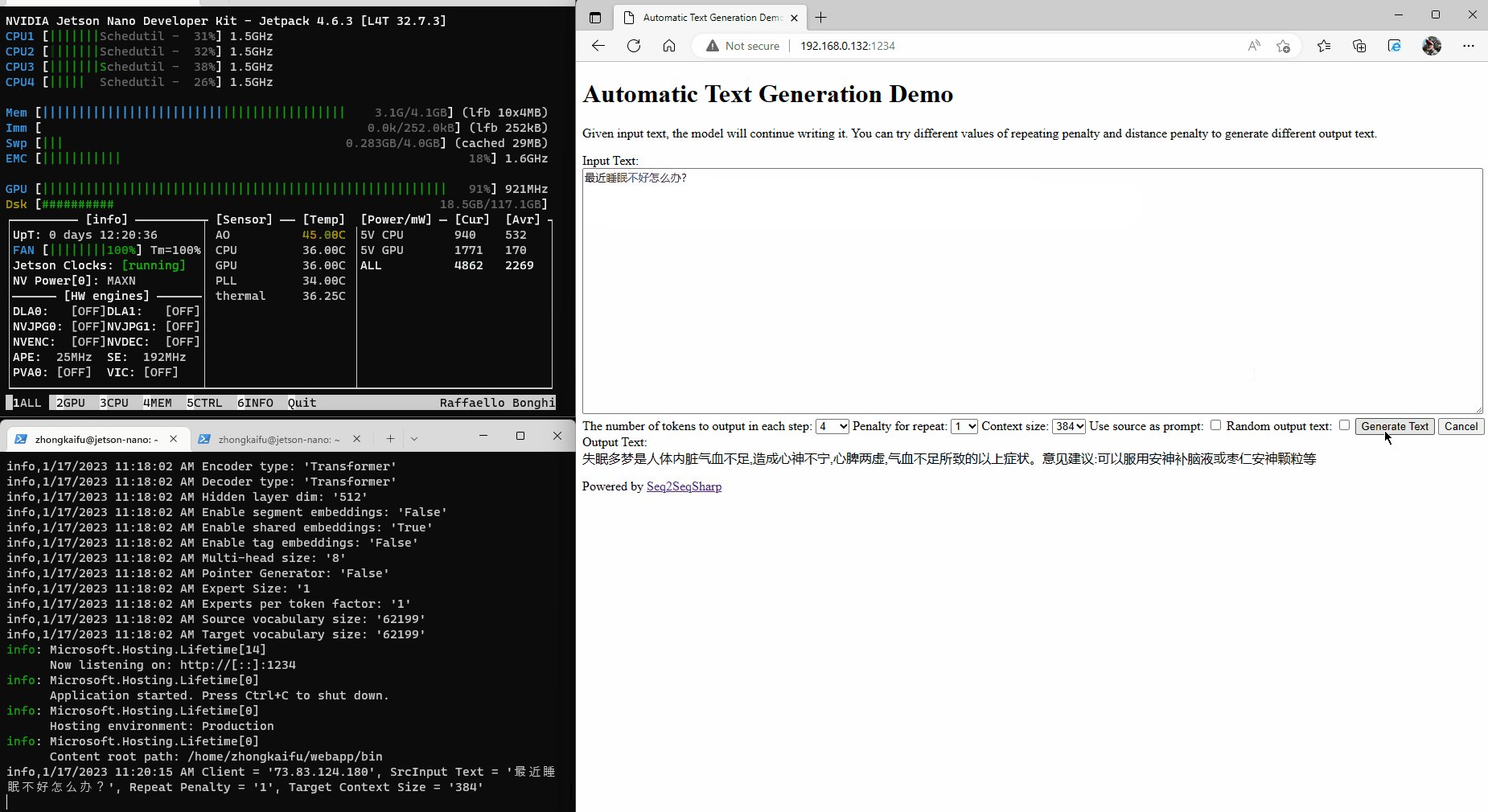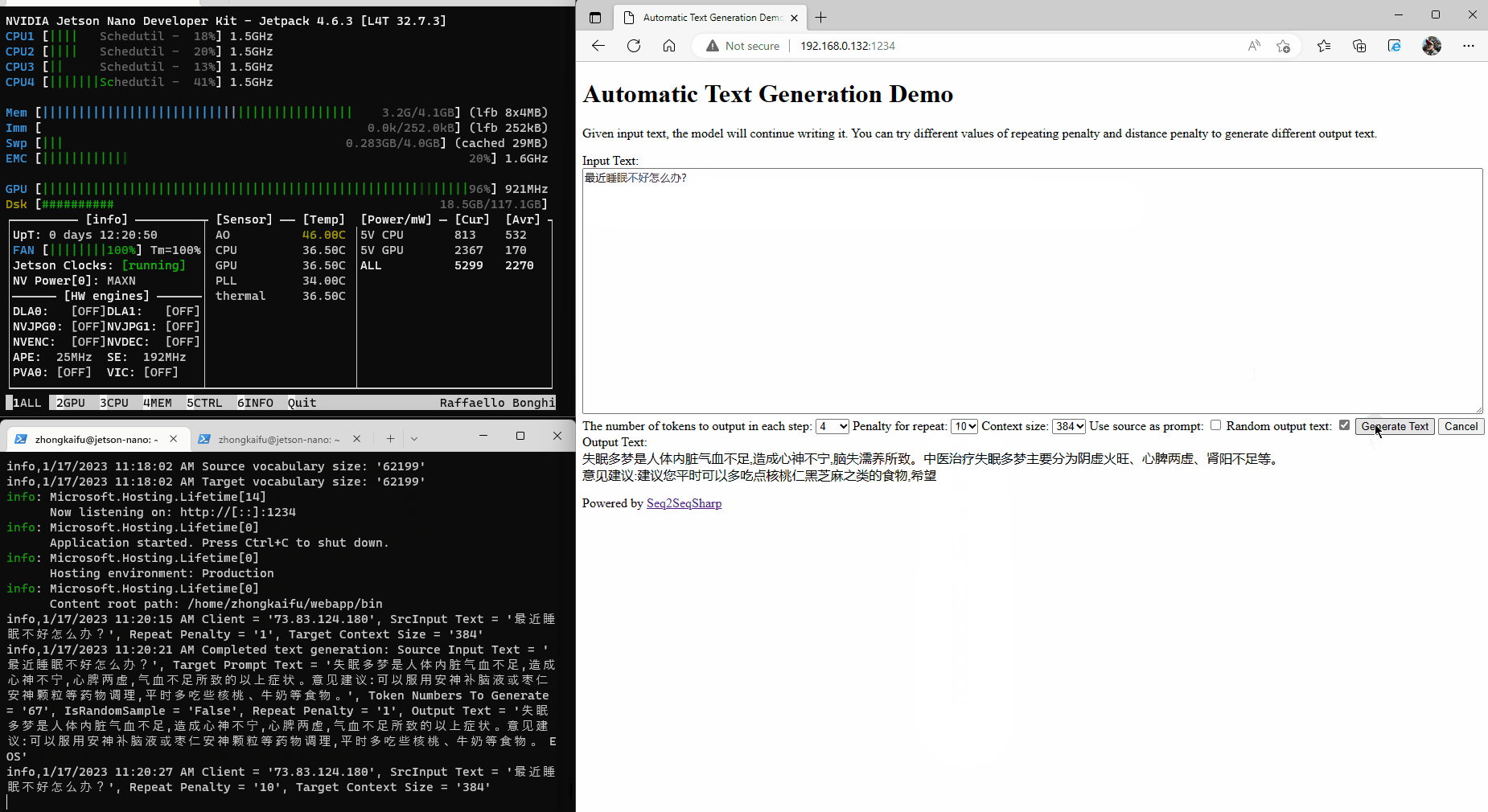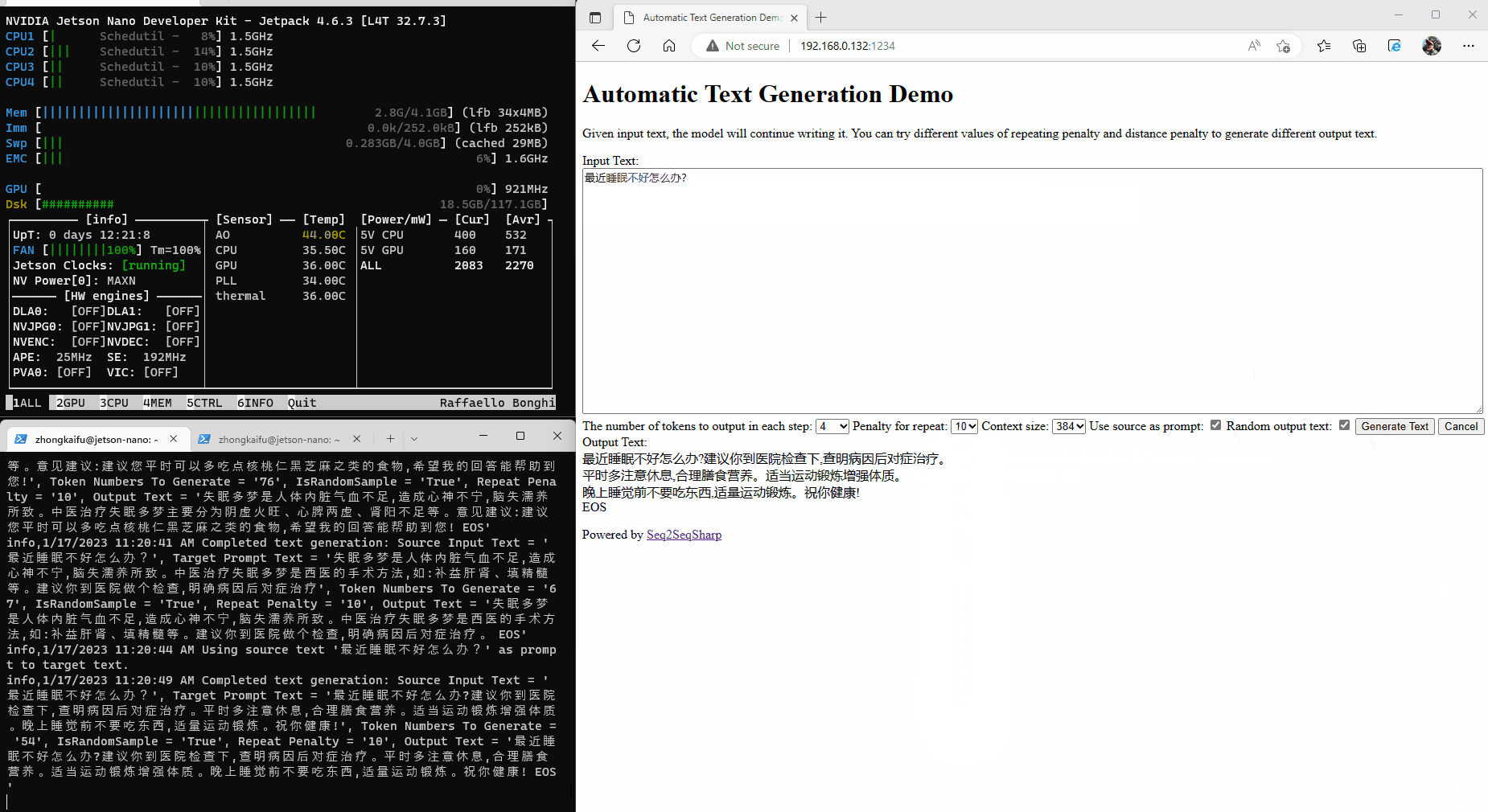
Built-in Tags
Seq2SeqSharp has several built-in tokens and they are used for certain purposes.
| Token | Comments |
| ------- | --------------------------------------------------------- |
| </s> | The end of the sequence |
| <s> | The beginning of the sequence |
| <unk> | OOV token |
| [SEP] | The token used to split input sequence into many segments |
| [CLS] | The token used to predict classification |
Tag Embeddings
Seq2SeqSharp has some built-in special embeddings, such as position embeddings and segment embeddings, it also has a another type of special embeddings called "Tag embeddings". When this feature is enabled (EnableTagEmbeddings == true), tokens included in certain tags will add the corresponding tag embeddings into their input embeddings. Here is an example:
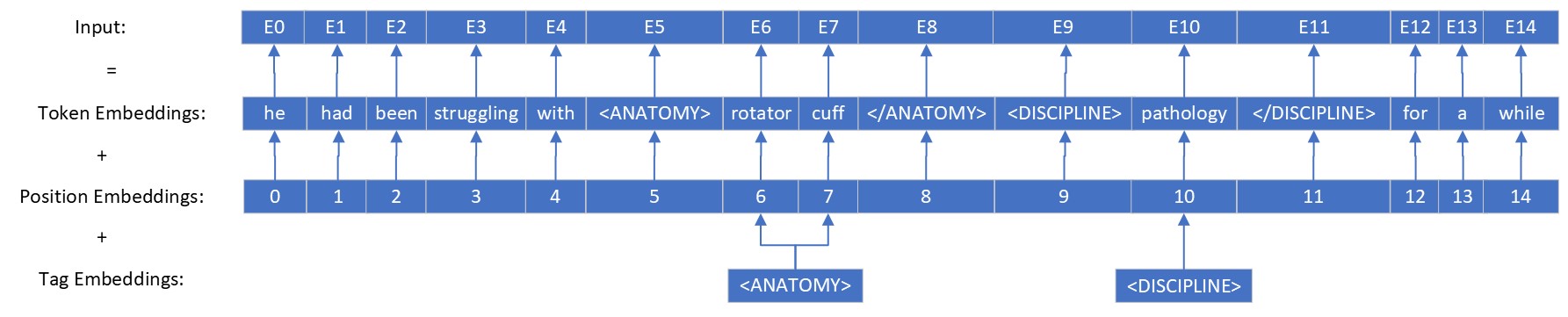
The embedding of <ANATOMY> will be added to the embedding of token "rotator" and "cuff" and the embedding of <DISCIPLINE> will be added to the embedding of token "pathology".
The tags in the embedding could be in source or target vocabulary. They can be recursive and all relative tags' embeddings will be added to the input. For example: <TAG1> Token1 <TAG2> Token2 </TAG2> </TAG1>. For "Token2", both TAG1's embeddings and TAG2's embeddings will be applied to its input embedding. However, for "Token1", only TAG1's embedding will be added to its input embedding.
Build Your Layers
Benefit from automatic differentiation, tensor based compute graph and other features, you can easily build your customized layers by a few code. The only thing you need to implment is forward part, and the framework will automatically build the corresponding backward part for you, and make the network could run on multi-GPUs or CPUs.
Here is an example about scaled multi-heads attention component which is the core part in Transformer model.
/// <summary>
/// Scaled multi-heads attention component with skip connectioned feed forward layers
/// </summary>
/// <param name="inputQ">The input Q tensor</param>
/// <param name="inputK">The input K tensor</param>
/// <param name="inputV">The input V tensor</param>
/// <param name="keyMask">The mask for softmax</param>
/// <param name="batchSize">Batch size of input data set</param>
/// <param name="graph">The instance of computing graph</param>
/// <returns>Transformered output tensor</returns>
public (IWeightTensor, IWeightTensor) Perform(IWeightTensor inputQ, IWeightTensor inputK, IWeightTensor inputV, IWeightTensor keyMask, int batchSize, IComputeGraph graph, bool outputAttenWeights = false)
{
using IComputeGraph g = graph.CreateSubGraph($"{m_name}_MultiHeadAttention");
int seqLenQ = inputQ.Rows / batchSize;
// SeqLenK must be euqal to SeqLenV
int seqLenK = inputK.Rows / batchSize;
int seqLenV = inputV.Rows / batchSize;
IWeightTensor inputQNorm = layerNormQ.Norm(inputQ, g);
//Input projections
IWeightTensor allQ = g.View(g.Affine(inputQNorm, Q, Qb), dims: new long[] { batchSize, seqLenQ, m_multiHeadNum, m_d });
IWeightTensor allK = g.View(g.Affine(inputK, K, Kb), dims: new long[] { batchSize, seqLenK, m_multiHeadNum, m_d });
IWeightTensor allV = g.View(g.Affine(inputV, V, Vb), dims: new long[] { batchSize, seqLenV, m_multiHeadNum, m_d });
//Multi-head attentions
IWeightTensor Qs = g.View(g.AsContiguous(g.Transpose(allQ, 1, 2)), dims: new long[] { batchSize * m_multiHeadNum, seqLenQ, m_d });
IWeightTensor Ks = g.View(g.AsContiguous(g.Transpose(g.Transpose(allK, 1, 2), 2, 3)), dims: new long[] { batchSize * m_multiHeadNum, m_d, seqLenK });
IWeightTensor Vs = g.View(g.AsContiguous(g.Transpose(allV, 1, 2)), dims: new long[] { batchSize * m_multiHeadNum, seqLenV, m_d });
// Scaled softmax
float scale = 1.0f / (float)(Math.Sqrt(m_d));
var attn = g.MulBatch(Qs, Ks, scale);
attn = g.View(attn, dims: new long[] { batchSize, m_multiHeadNum, seqLenQ, seqLenK });
if (keyMask != null)
{
attn = g.Add(attn, keyMask, runGradient1: true, runGradient2: false, inPlace: true);
}
var attnProbs = g.Softmax(attn, inPlace: true);
IWeightTensor sumAttnWeights = null;
if (outputAttenWeights)
{
//Merge all attention probs over multi-heads
sumAttnWeights = g.Sum(attnProbs, 1, runGradient: false);
sumAttnWeights = graph.Mul(sumAttnWeights, 1.0f / (float)m_multiHeadNum, runGradient: false);
sumAttnWeights = graph.View(sumAttnWeights, false, new long[] { batchSize * seqLenQ, seqLenK });
}
attnProbs = g.View(attnProbs, dims: new long[] { batchSize * m_multiHeadNum, seqLenQ, seqLenK });
IWeightTensor o = g.View(g.MulBatch(attnProbs, Vs), dims: new long[] { batchSize, m_multiHeadNum, seqLenQ, m_d });
IWeightTensor W = g.View(g.AsContiguous(g.Transpose(o, 1, 2)), dims: new long[] { batchSize * seqLenQ, m_multiHeadNum * m_d });
// Output projection
IWeightTensor finalAttResults = g.Dropout(g.Affine(W, W0, b0), batchSize, m_dropoutRatio, inPlace: true);
IWeightTensor result = graph.Add(finalAttResults, inputQ, inPlace: true);
return (result, sumAttnWeights);
}
Build Your Operations
Seq2SeqSharp includes many built-in operations for neural networks. You can visit IComputeGraph.cs to get interfaces and ComputeGraphTensor.cs to get implementation.
You can also implement your customized operations. Here is an example for "w1 * w2 + w3 * w4" in a single operation. The forward part includes 1) create result tensor and 2) call inner-operation "Ops.MulMulAdd".
And the backward part is in "backward" action that the gradients of each input tensor(w?) will be added by the product between weights of input tensor(w?) and gradients of the output tensor(res).
If the operations is for forward part only, you can completely ignore "backward" action.
public IWeightTensor EltMulMulAdd(IWeightTensor w1, IWeightTensor w2, IWeightTensor w3, IWeightTensor w4)
{
var m1 = w1 as WeightTensor;
var m2 = w2 as WeightTensor;
var m3 = w3 as WeightTensor;
var m4 = w4 as WeightTensor;
var res = m_weightTensorFactory.CreateWeightTensor(m1.Sizes, m_deviceId, name: $"{GetHashString(w1.Name, w2.Name, w3.Name, w4.Name)}.EltMulMulAdd");
VisualizeNodes(new IWeightTensor[] { w1, w2, w3, w4 }, res);
Ops.MulMulAdd(res.TWeight, m1.TWeight, m2.TWeight, m3.TWeight, m4.TWeight);
if (m_needsBackprop)
{
Action backward = () =>
{
res.ReleaseWeight();
m1.AddMulGradient(m2.TWeight, res.TGradient);
m2.AddMulGradient(m1.TWeight, res.TGradient);
m3.AddMulGradient(m4.TWeight, res.TGradient);
m4.AddMulGradient(m3.TWeight, res.TGradient);
res.Dispose();
};
this.m_backprop.Add(backward);
}
return res;
}
Build Your Networks
Besides operations and layers, you can also build your customized networks by leveraging BaseSeq2SeqFramework. The built-in AttentionSeq2Seq is a good example to show you how to do it. Basically, it includes the follows steps:
- Define model meta data, such as hidden layer dimension, embedding diemnsion, layer depth and so on. It should be inherited from IModelMetaData interface. You can look at Seq2SeqModelMetaData.cs as an example.
public class Seq2SeqModelMetaData : IModelMetaData
{
public int HiddenDim;
public int EmbeddingDim;
public int EncoderLayerDepth;
public int DecoderLayerDepth;
public int MultiHeadNum;
public EncoderTypeEnums EncoderType;
public Vocab Vocab;
}
- Create the class for your network and make sure it is inherited from BaseSeq2SeqFramework class at first, and then define layers, tensors for your network. Seq2SeqSharp has some built-in layers, so you can just use them or create your customized layers by instruction in above. In order to support multi-GPUs, these layers and tensors should be wrapped by MultiProcessorNetworkWrapper class. Here is an example:
private MultiProcessorNetworkWrapper<IWeightTensor> m_srcEmbedding; //The embeddings over devices for target
private MultiProcessorNetworkWrapper<IWeightTensor> m_tgtEmbedding; //The embeddings over devices for source
private MultiProcessorNetworkWrapper<IEncoder> m_encoder; //The encoders over devices. It can be LSTM, BiLSTM or Transformer
private MultiProcessorNetworkWrapper<AttentionDecoder> m_decoder; //The LSTM decoders over devices
private MultiProcessorNetworkWrapper<FeedForwardLayer> m_decoderFFLayer; //The feed forward layers over devices after LSTM layers in decoder
- Initialize those layers and tensors your defined in above. You should pass variables you defined in model meta data to the constructors of layers and tensors. Here is an example in AttentionSeq2Seq.cs
private bool CreateTrainableParameters(IModelMetaData mmd)
{
Logger.WriteLine($"Creating encoders and decoders...");
Seq2SeqModelMetaData modelMetaData = mmd as Seq2SeqModelMetaData;
RoundArray<int> raDeviceIds = new RoundArray<int>(DeviceIds);
if (modelMetaData.EncoderType == EncoderTypeEnums.BiLSTM)
{
m_encoder = new MultiProcessorNetworkWrapper<IEncoder>(
new BiEncoder("BiLSTMEncoder", modelMetaData.HiddenDim, modelMetaData.EmbeddingDim, modelMetaData.EncoderLayerDepth, raDeviceIds.GetNextItem()), DeviceIds);
m_decoder = new MultiProcessorNetworkWrapper<AttentionDecoder>(
new AttentionDecoder("AttnLSTMDecoder", modelMetaData.HiddenDim, modelMetaData.EmbeddingDim, modelMetaData.HiddenDim * 2, modelMetaData.DecoderLayerDepth, raDeviceIds.GetNextItem()), DeviceIds);
}
else
{
m_encoder = new MultiProcessorNetworkWrapper<IEncoder>(
new TransformerEncoder("TransformerEncoder", modelMetaData.MultiHeadNum, modelMetaData.HiddenDim, modelMetaData.EmbeddingDim, modelMetaData.EncoderLayerDepth, m_dropoutRatio, raDeviceIds.GetNextItem()), DeviceIds);
m_decoder = new MultiProcessorNetworkWrapper<AttentionDecoder>(
new AttentionDecoder("AttnLSTMDecoder", modelMetaData.HiddenDim, modelMetaData.EmbeddingDim, modelMetaData.HiddenDim, modelMetaData.DecoderLayerDepth, raDeviceIds.GetNextItem()), DeviceIds);
}
m_srcEmbedding = new MultiProcessorNetworkWrapper<IWeightTensor>(new WeightTensor(new long[2] { modelMetaData.Vocab.SourceWordSize, modelMetaData.EmbeddingDim }, raDeviceIds.GetNextItem(), normal: true, name: "SrcEmbeddings", isTrainable: true), DeviceIds);
m_tgtEmbedding = new MultiProcessorNetworkWrapper<IWeightTensor>(new WeightTensor(new long[2] { modelMetaData.Vocab.TargetWordSize, modelMetaData.EmbeddingDim }, raDeviceIds.GetNextItem(), normal: true, name: "TgtEmbeddings", isTrainable: true), DeviceIds);
m_decoderFFLayer = new MultiProcessorNetworkWrapper<FeedForwardLayer>(new FeedForwardLayer("FeedForward", modelMetaData.HiddenDim, modelMetaData.Vocab.TargetWordSize, dropoutRatio: 0.0f, deviceId: raDeviceIds.GetNextItem()), DeviceIds);
return true;
}
- Implement forward part only for your network and the BaseSeq2SeqFramework will handle all other things, such as backward propagation, parameters updates, memory management, computing graph managment, corpus shuffle & batching, saving/loading for model, logging & monitoring, checkpoints and so on. Here is an example in AttentionSeq2Seq.cs as well.
/// <summary>
/// Run forward part on given single device
/// </summary>
/// <param name="computeGraph">The computing graph for current device. It gets created and passed by the framework</param>
/// <param name="srcSnts">A batch of input tokenized sentences in source side</param>
/// <param name="tgtSnts">A batch of output tokenized sentences in target side</param>
/// <param name="deviceIdIdx">The index of current device</param>
/// <returns>The cost of forward part</returns>
private float RunForwardOnSingleDevice(IComputeGraph computeGraph, List<List<string>> srcSnts, List<List<string>> tgtSnts, int deviceIdIdx)
{
(IEncoder encoder, AttentionDecoder decoder, IWeightTensor srcEmbedding, IWeightTensor tgtEmbedding, FeedForwardLayer decoderFFLayer) = GetNetworksOnDeviceAt(deviceIdIdx);
// Reset networks
encoder.Reset(computeGraph.GetWeightFactory(), srcSnts.Count);
decoder.Reset(computeGraph.GetWeightFactory(), tgtSnts.Count);
// Encoding input source sentences
IWeightTensor encodedWeightMatrix = Encode(computeGraph.CreateSubGraph("Encoder"), srcSnts, encoder, srcEmbedding);
// Generate output decoder sentences
return Decode(tgtSnts, computeGraph.CreateSubGraph("Decoder"), encodedWeightMatrix, decoder, decoderFFLayer, tgtEmbedding);
}
Now you already have your customized network and you can play it. See Progream.cs in Seq2SeqConsole project about how to load corpus and vocabulary, and create network for training.
How To Play Your Network
In Seq2SeqConsole project, it shows you how to initialize and train your network. Here are few steps about how to do it.
Seq2SeqCorpus trainCorpus = new Seq2SeqCorpus(corpusFilePath: opts.TrainCorpusPath, srcLangName: opts.SrcLang, tgtLangName: opts.TgtLang, batchSize: opts.BatchSize,
maxSrcSentLength: opts.MaxSrcTrainSentLength, maxTgtSentLength: opts.MaxTgtTrainSentLength, paddingEnums: paddingType);
// Load valid corpus
Seq2SeqCorpus validCorpus = string.IsNullOrEmpty(opts.ValidCorpusPath) ? null : new Seq2SeqCorpus(opts.ValidCorpusPath, opts.SrcLang, opts.TgtLang, opts.ValBatchSize, opts.MaxSrcTestSentLength, opts.MaxTgtTestSentLength, paddingEnums: paddingType);
// Create learning rate
ILearningRate learningRate = new DecayLearningRate(opts.StartLearningRate, opts.WarmUpSteps, opts.WeightsUpdateCount);
// Create optimizer
IOptimizer optimizer = null;
if (String.Equals(opts.Optimizer, "Adam", StringComparison.InvariantCultureIgnoreCase))
{
optimizer = new AdamOptimizer(opts.GradClip, opts.Beta1, opts.Beta2);
}
else
{
optimizer = new RMSPropOptimizer(opts.GradClip, opts.Beta1);
}
// Create metrics
List<IMetric> metrics = new List<IMetric>
{
new BleuMetric(),
new LengthRatioMetric()
};
if (!String.IsNullOrEmpty(opts.ModelFilePath) && File.Exists(opts.ModelFilePath))
{
//Incremental training
Logger.WriteLine($"Loading model from '{opts.ModelFilePath}'...");
ss = new Seq2Seq(opts);
}
else
{
// Load or build vocabulary
Vocab srcVocab = null;
Vocab tgtVocab = null;
if (!string.IsNullOrEmpty(opts.SrcVocab) && !string.IsNullOrEmpty(opts.TgtVocab))
{
Logger.WriteLine($"Loading source vocabulary from '{opts.SrcVocab}' and target vocabulary from '{opts.TgtVocab}'. Shared vocabulary is '{opts.SharedEmbeddings}'");
if (opts.SharedEmbeddings == true && (opts.SrcVocab != opts.TgtVocab))
{
throw new ArgumentException("The source and target vocabularies must be identical if their embeddings are shared.");
}
// Vocabulary files are specified, so we load them
srcVocab = new Vocab(opts.SrcVocab);
tgtVocab = new Vocab(opts.TgtVocab);
}
else
{
Logger.WriteLine($"Building vocabulary from training corpus. Shared vocabulary is '{opts.SharedEmbeddings}'");
// We don't specify vocabulary, so we build it from train corpus
(srcVocab, tgtVocab) = trainCorpus.BuildVocabs(opts.VocabSize, opts.SharedEmbeddings);
}
//New training
ss = new Seq2Seq(opts, srcVocab, tgtVocab);
}
// Add event handler for monitoring
ss.StatusUpdateWatcher += ss_StatusUpdateWatcher;
ss.EvaluationWatcher += ss_EvaluationWatcher;
// Kick off training
ss.Train(maxTrainingEpoch: opts.MaxEpochNum, trainCorpus: trainCorpus, validCorpus: validCorpus, learningRate: learningRate, optimizer: optimizer, metrics: metrics);
Todo List
If you are interested in below items, please let me know. Becuase African proverb says "If you want to go fast, go alone. If you want to go far, go together" 😃
Support Mac Devices
And More...
Star History
| Product | Versions Compatible and additional computed target framework versions. |
|---|---|
| .NET | net8.0 is compatible. net8.0-android was computed. net8.0-browser was computed. net8.0-ios was computed. net8.0-maccatalyst was computed. net8.0-macos was computed. net8.0-tvos was computed. net8.0-windows was computed. |
-
net8.0
- AdvUtils (>= 2.7.0)
- Microsoft.CSharp (>= 4.7.0)
- Microsoft.Extensions.Caching.Memory (>= 8.0.0)
- protobuf-net (>= 3.2.30)
- System.Data.DataSetExtensions (>= 4.5.0)
- System.Runtime.Caching (>= 8.0.0)
- TensorSharp (>= 2.8.6)
- TensorSharp.CUDA (>= 2.8.6)
NuGet packages
This package is not used by any NuGet packages.
GitHub repositories
This package is not used by any popular GitHub repositories.
| Version | Downloads | Last updated | |
|---|---|---|---|
| 2.8.19 | 72 | 11/18/2024 | |
| 2.8.18 | 74 | 11/14/2024 | |
| 2.8.17 | 100 | 10/21/2024 | |
| 2.8.16 | 78 | 10/21/2024 | |
| 2.8.15 | 104 | 10/18/2024 | |
| 2.8.14 | 77 | 10/7/2024 | |
| 2.8.13 | 94 | 10/7/2024 | |
| 2.8.12 | 82 | 10/7/2024 | |
| 2.8.11 | 131 | 9/9/2024 | |
| 2.8.9 | 151 | 6/2/2024 | |
| 2.8.8 | 172 | 4/5/2024 | |
| 2.8.7 | 137 | 4/3/2024 | |
| 2.8.6 | 199 | 1/6/2024 | |
| 2.8.5 | 136 | 1/6/2024 | |
| 2.8.3 | 132 | 1/6/2024 | |
| 2.8.2 | 140 | 1/6/2024 | |
| 2.8.1 | 137 | 1/6/2024 | |
| 2.8.0 | 140 | 1/5/2024 | |
| 2.5.0 | 573 | 5/9/2022 | |
| 1.0.0 | 370 | 8/16/2021 |
Seq2SeqSharp is a tensor based fast & flexible encoder-decoder deep neural network framework written by .NET (C#). It can be used for sequence-to-sequence task, sequence-labeling task and sequence-classification task and other NLP tasks. Seq2SeqSharp supports both CPUs (x86, x64 and ARM64) and GPUs. It's powered by .NET core, so Seq2SeqSharp can run on both Windows and Linux without any modification and recompilation.